
Esta es la documentación oficial para el uso del supercomputador Picasso. Si tienes algún problema que no esté especificado en esta documentación o en la sección de preguntas frecuentes, por favor, ponte en contacto a través de
soporte@scbi.uma.es
Índice
- 1 - Cita y agradecimientos
- 2 - Acerca de Picasso: Hardware y Sistemas de Ficheros
- 3 - Inicio de sesión en Picasso
- 4 - Cómo enviar trabajos
- 4.1 - Preparación para enviar un trabajo
- 4.2 - Modificación de recursos y límites
- 4.3 - Solicitud de GPUs
- 4.4 - Generador de trabajos de ejemplo
- 4.5 - Envío de un trabajo
- 4.6 - Array Jobs: cómo enviar muchos trabajos
- 4.7 - Monitoreo de trabajos en cola
- 4.8 - Cancelación de trabajos
- 4.9 - Uso del sistema de ficheros LOCALSCRATCH
- 5 - Copiar ficheros desde/hacia Picasso
- 6 - Software
- 7 - Comandos propios de Picasso
- 8 - Preguntas frecuentes
- 8.1 - ¿Cuántos recursos debería solicitar para mis trabajos?
- 8.2 - Mensaje de error: Conection refused/The network is not available
- 8.3 - Mensaje de error: Remote host identification has changed
- 8.4 - ¿Cómo cambio mi contraseña?
- 8.5 - ¿Por qué mi proceso en el nodo de inicio de sesión está siendo detenido?
- 8.6 - ¿Por qué mi trabajo está en cola durante tanto tiempo?
- 8.7 - ¿Por qué mi trabajo no obtiene los recursos que solicité?
- 8.8 - Necesito más tiempo para mi trabajo
- 8.9 - ¿Por qué ha fallado mi trabajo?
- 8.10 - Mensaje de error: cnf
- 8.11 - ¿Por qué se ha cancelado mi trabajo?
- 8.12 - Mensaje de error: Out of memory handler
- 8.13 - ¿Por qué no puedo editar ni crear nuevos ficheros?
- 8.14 - Necesito más espacio o cuota de ficheros
1 - Cita y agradecimientos
Si utilizas nuestros recursos, debes dar reconocimiento a este servicio en tus publicaciones. Por favor, agrega un texto como este:
The author thankfully acknowledges the computer resources (Picasso Supercomputer), technical expertise and
assistance provided by the SCBI (Supercomputing and Bioinformatics) center of the University of Malaga
Por favor, infórmanos sobre aquellas publicaciones que utilizaron nuestros recursos, ya que esto nos permite solicitar ampliaciones para Picasso, de las que también te podrás beneficiar. Aprovecharemos la oportunidad para felicitarte.
2 - Acerca de Picasso: Hardware y Sistemas de Ficheros
2.1 - Visión general del sistema
Los recursos de supercomputación del SCBI comprenden un conjunto de nodos de computación con diferentes características. Sin embargo, todas esas máquinas están unificadas detrás del sistema de colas Slurm, por lo que no tendrás que preocuparte por sus diferencias. Bastará con crear un script SBATCH (un archivo de texto con una sintaxis especial).
El script se utiliza para solicitar los recursos (tiempo, CPUs, memoria, GPUs, etc.) de los que tu trabajo hará uso. Es importante que los recursos solicitados puedan utilizarse de manera óptima, ya que esto facilitará que tu trabajo empiece a resolver lo antes posible. Las máquinas con características especiales como más memoria o GPUs son escasas, y debido a esto son más difíciles de reservar.
Una vez que tengas tu script escrito, debes enviarlo al sistema de cola. Luego, el sistema de cola analizará tu solicitud y enviará el trabajo a las computadoras apropiadas. Hay algunos ejemplos en el capítulo Cómo enviar trabajos. Si tienes alguna pregunta, por favor, no dudes en contactarnos en soporte@scbi.uma.es y haremos todo lo posible para ayudarte.
2.2 - Recursos de hardware
2.2.1 - Recursos totales de cómputo
En Picasso tenemos los siguientes nodos:
- Nodos sd: 126 x nodos SD530: 52 núcleos (Intel Xeon Gold 6230R @ 2.10GHz), 192 GB de RAM. Red InfiniBand HDR100. 950 GB de discos localescratch.
- Nodos bl: 24 x nodos Bull R282-Z90: 128 núcleos (AMD EPYC 7H12 @ 2.6GHz), 2 TB de RAM. Red InfiniBand HDR200. 3.5 TB de discos localescratch.
- Nodos sr: 156 x nodos Lenovo SR645: 128 núcleos (AMD EPYC 7H12 @ 2.6GHz), 512 GB de RAM. Red InfiniBand HDR100. 900 GB de discos localescratch.
- Nodos bc: 34 x nodos Lenovo SR645 v3: 256 núcleos (AMD EPYC 9754 @ 2.25GHz), 768 GB de RAM. Red InfiniBand 2x HDR200. 4 TB de discos localescratch.
- Nodos exa (GPU): 4 x nodos DGX-A100: 8 GPUs (Nvidia A100), 1 TB de RAM. Red InfiniBand HDR200. 14 TB de discos localscratch.
2.2.2 - Recursos disponibles
Tanto el sistema operativo como el sistema de ficheros requieren parte de los recursos (RAM) disponibles en los nodos. Por esta razón, los recursos (CPUs, RAM) que se pueden solicitar para cada nodo a través del sistema de cola son los siguientes:
- Nodos sd: CPUs: 52 núcleos. RAM: 182 GB.
- Nodos bl: CPUs: 128 núcleos. RAM: 1855 GB.
- Nodos sr: CPUs: 128 núcleos. RAM: 439 GB.
- Nodos bc: CPUs: 256 núcleos. RAM: 683 GB.
- Nodos exa (GPU): CPUs: 128 núcleos. RAM: 878 GB.
IMPORTANTE: Los recursos de los nodos Exa se distribuyen entre las 8 GPUs de cada nodo, por lo que en el uso ideal no se deben solicitar más de 16 núcleos y 109 GB de RAM por GPU solicitada.
IMPORTANTE: Si tienes la intención de utilizar muchos ficheros (por ejemplo, más de 15000) para resolver un problema (por ejemplo, en entrenamiento de IA), debes contactar con nosotros primero, ya que puede provocar problemas graves en el rendimiento general de Picasso.
2.3 - Sistema de ficheros
2.3.1 - Sistemas de ficheros de Picasso
El sistema de ficheros de Picasso está dividido en dos espacios físicamente independientes. En ambos, como usuario de Picasso, obtendrás una cuota de disco.
HOME (Sistema de almacenamiento permanente): Aquí deberías almacenar datos de entrada, tus propios scripts desarrollados, resultados dos finales y otros datos importantes. Para volver a tu home, puedes ingresar alguno de los siguientes comandos:
cdcd ~cd $HOMEFSCRATCH (Sistema de almacenamiento temporal): FSCRATCH es un almacenamiento de alta velocidad en el que deberías lanzar tus trabajos. Puedes encontrar información relevante sobre el uso de FSCRATCH en la sección Sistema de ficheros de scratch rápido (FSCRATCH). Ten en cuenta que FSCRATCH es un almacenamiento temporal, y los ficheros antiguos se eliminarán periódicamente. POR FAVOR, NO LO USES PARA ALMACENAR DATOS IMPORTANTES. Para ir a tu espacio de fscratch puedes ingresar:
cd $FSCRATCH
2.3.2 - Cuota de ficheros y espacio
Además de la limitación de espacio en cada uno de los dos espacios (home y fscratch), también hay una cuota de ficheros. Mientras que la cuota de espacio determina la limitación en términos de gigabytes escritos, la cuota de ficheros determina la limitación en términos de número de ficheros escritos.
La cuota funciona en dos pasos, que se llaman soft quota y hard quota:
- Soft quota: Cuando excedes tu cuota, recibirás un mensaje de advertencia cada vez que inicies sesión en Picasso. En la figura siguiente, puedes ver un ejemplo de alguien que excede la softquota de espacio libre.

- Hard quota: Cuando excedes tu cuota por mucho, encontrarás un límite estricto que no te permitirá escribir más ficheros, incluso si estabas dentro del periodo de gracia de 7 días de la soft quota.
Una vez que se alcanza la cuota (de espacio o de ficheros), tienes 7 días para volver a la situación normal. Si pasan esos 7 días o se alcanza la hard quota, la escritura en disco se bloqueará.
Para verificar tus cuotas, puedes ejecutar el comando:
quota
mmlsquota
2.3.3 - Sistema de ficheros de scratch rápido (FSCRATCH) y política de purga
- Acerca de FSCRATCH
El sistema de ficheros FSCRATCH (Fast Scratch) debe usarse para acelerar los trabajos, especialmente aquellos que hacen un uso intenso del almacenamiento. Este espacio está concebido como un sistema de ficheros pseudo-volátil. Esto significa que los datos almacenados aquí se eliminarán periódica y automáticamente, así que no deberías usarlo para almacenar ficheros importantes.:
Para ir a FSCRATCH, escribe
cd $FSCRATCH
Puedes copiar carpetas de HOME a FSCRATCH usando un comando como:
cp -r $HOME/path/to/your/folder/in/home $FSCRATCH/path/to/target/folder
o desde FSCRATCH a HOME usando
cp -r $FSCRATCH/path/to/your/folder/in/fscratch $HOME/path/to/target/folder
No olvides copiar los datos de salida importantes de vuelta a tu HOME, porque se eliminarán después de algunas semanas.
- Política de purga
Los ficheros que no se hayan utilizado durante más de dos meses se eliminarán automáticamente.
Los ficheros no se eliminarán después de exactamente dos meses, pero los ficheros que no se hayan utilizado durante dos meses estarán sujetos a eliminación en cualquier momento sin previo aviso. La purga se activa en función del porcentaje de uso total de FSCRATCH.
Si no estás seguro de cómo usar FSCRATCH, por favor contáctanos a soporte@scbi.uma.es.
2.3.4 - Sistema de ficheros de scratch local
Hay algunos nodos que tienen un sistema de ficheros de scratch local llamado LOCALSCRATCH. Este scratch local es aún más rápido que el sistema de ficheros fscratch, pero tiene una desventaja principal: solo es accesible desde cada nodo, por lo que no puedes acceder a él desde la máquina donde inicias sesión, sino solo desde el script SBATCH que enviarás al sistema de cola (usando la variable de entorno $LOCALSCRATCH).
El scratch local es muy rápido y puede acelerar sustancialmente algunos trabajos cuando se utiliza. Y es imprescindible cuando un trabajo necesita escribir muchos ficheros o hacer un uso intensivo del disco. También puedes encontrar un ejemplo en la sección Cómo enviar trabajos.
Si crees que necesitas acceso al scratch local y no estás seguro de cómo usarlo, por favor contáctanos a soporte@scbi.uma.es.
2.3.5 - Política de copias de seguridad
NOTA IMPORTANTE: Es importante que sigas una política de copias de seguridad responsable. No somos responsables de la pérdida de datos almacenados en nuestros sistemas, por lo que si tus datos son importantes, deberías tener copias de seguridad en tu propia máquina o sistema de copias de seguridad. Como cortesía, mantenemos una copia de seguridad de los ficheros almacenados en el directorio de inicio, pero no quedan garantizadas, ni podemos hacer copias de seguridad de todo el espacio disponible. Puedes seguir estas pautas de copias de seguridad si lo deseas:
- Es una buena práctica usar un sistema de control de versiones para tus propios programas y scripts. Git puede ser una buena solución (https://git-scm.com/). Los sistemas de control de versiones ayudan a los programadores a llevar un seguimiento de todos los cambios realizados en el código fuente, scripts, etc. Cada vez que realizas un cambio en un archivo, puedes guardarlo en tu sistema de control de versiones con alguna descripción textual, y luego puedes ver esos cambios en cualquier momento o retroceder a una versión anterior. Esto no es una copia de seguridad real, pero es una especie de ella.
- Mantén diferentes copias de seguridad, de diferentes fechas. Las copias de seguridad también son útiles si eliminas o modificas un archivo por error.
- Almacena las copias de seguridad en lugares físicos diferentes. De esta manera, si la ubicación principal de tu computadora sufre un desastre, podrías acceder a otra copia que tengas en otro lugar.
- Intenta acceder a tus datos de copia de seguridad periódicamente. Puedes hacer muchas copias de seguridad, pero si no son accesibles, no son útiles.
3 - Iniciar sesión en Picasso
Como la mayoría de los supercomputadores, Picasso se basa en una distribución de Linux, en este caso openSuse Leap 15.4. El acceso remoto al sistema se realiza mediante el protocolo SSH (puerto 22), conectándose a un servidor de inicio de sesión. En este servidor encontrarás todos los compiladores y herramientas necesarias para preparar y enviar tus trabajos al sistema de cola.
3.1 - Conexión SSH
Para conectarte al servidor de inicio de sesión, necesitarás ingresar el siguiente comando en la terminal del sistema (puede ser CMD o PowerShell en Windows, o la terminal de Linux y MacOs):
ssh @picasso.scbi.uma.es
Por ejemplo, si tu nombre de usuario es myuser, deberías ingresar:
myuser@picasso.scbi.uma.es
Después de esto, se te pedirá que ingreses tu contraseña. Cuando la ingreses, verás que no aparece nada en la pantalla, pero se está registrando. Presiona enter cuando hayas terminado, y la conexión debería establecerse.
Advertencia: Si fallas al ingresar la contraseña varias veces, el sistema bloqueará tu IP. Se desbloqueará después de 30 minutos. Si vuelves a fallar varias veces, la IP será bloqueada permanentemente. Tendrás que contactarnos en soporte@scbi.uma.es para desbloquearla.
Consejo: si tienes problemas de sesión y tu conexión se interrumpe después de un corto tiempo de inactividad o debido a la estabilidad de la conexión a Internet; debes incluir un comando de mantener viva la conexión en tus conexiones:
ssh ServerAliveInterval=60 myuser@picasso.scbi.uma.es
3.2 - MobaXTerm
Si no estás familiarizado con las terminales, tal vez puedas probar a usar el programa MobaXTerm. Es más fácil de usar y permite cosas como copiar un archivo usando el ratón.
3.3 - Aviso importante
NOTA IMPORTANTE: Cuando accedes a Picasso, estás ingresando en uno de nuestros nodos, el nodo de inicio de sesión. El nodo de inicio de sesión no es un lugar para ejecutar tu trabajo. Puede ser utilizado para construir scripts, compilar programas, probar que un comando complejo que vas a utilizar en el script SBATCH se está ejecutando correctamente, etc., pero NO para realizar trabajo real. Todos los programas lanzados serán automáticamente detenidos sin previo aviso cuando utilicen más de 10 minutos de tiempo de CPU.
El trabajo real debe ser enviado al sistema de cola (ver sección Cómo enviar trabajos).
4 - Cómo enviar trabajos
Nuestro sistema de cola actual es Slurm. Entonces, cualquier manual de Slurm te dará información más detallada sobre estos comandos. Esta es solo una guía de inicio rápido:
4.1 - Preparación para enviar un trabajo
Antes de enviar un trabajo al sistema de cola, solo tienes que escribir un pequeño archivo de script con un formato específico. Llamamos a este script script SBATCH. Aquí es donde se solicitan los recursos al sistema de cola y donde se colocan las sentencias de ejecución. Este script está escrito en lenguaje bash (el mismo que en la terminal).
En Picasso tenemos un comando para generar una plantilla para este tipo de scripts:
gen_sbatch_file script.sh "executing_command"
Este comando generará un script llamado "script.sh" con el comando "executing_command". Solo tienes que editar este archivo para ajustar los recursos que deseas solicitar, cargar los módulos y ajustar la declaración de ejecución. En la sección Modificación de recursos y límites veremos cómo hacerlo.
Cada software tiene su propia forma de llamarlo para resolver un trabajo, pero no te preocupes, ya que encontrarás todos los detalles en las instrucciones individuales, guías o ficheros readme de cada software.
4.2 - Modificación de recursos y límites
Aquí vamos a ver cómo modificar el script SBATCH de ejemplo generado con el comando:
gen_sbatch_file script.sh "executing_command"
Si ingresas a este archivo, verás algo como esto:
#!/usr/bin/env bash
# Leave only one comment symbol on selected options
# Those with two commets will be ignored:
# The name to show in queue lists for this job:
##SBATCH -J script_2.sh
# Number of desired cpus (can be in any node):
#SBATCH --ntasks=1
# Number of desired cpus (all in same node):
##SBATCH --cpus-per-task=1
# Amount of RAM needed for this job:
#SBATCH --mem=2gb
# The available nodes are:
# AMD nodes with 128 cores and 1800GB of usable RAM
# AMD nodes with 128 cores and 439GB of usable RAM
# Intel nodes with 52 cores and 187GB of usable RAM
# The time the job will be running:
#SBATCH --time=10:00:00
# If you need nodes with special features you can select a constraint.
# Please, use cal by default. You will be assigned a node that satisfies your requests.
#SBATCH --constraint=cal
# Change "cal" by "sd" if you want to use Intel nodes and by "sr" if you want to use AMD nodes.
##SBATCH --constraint=sd
##SBATCH --constraint=sr
# To use GPU, comment out the constraint line and uncomment the following line.
##SBATCH --gres=gpu:1
# Set output and error files
#SBATCH --error=job.%J.err
#SBATCH --output=job.%J.out
# Leave one comment in following line to make an array job. Then N jobs will be launched. In each one SLURM_ARRAY_TASK_ID will take one value from 1 to 100
##SBATCH --array=1-100
# To load some software (you can show the list with 'module avail'):
# module load software
# the program to execute with its parameters:
time executing_command
Primero que nada, debes saber que en bash todas las líneas que comienzan con "#" son comentarios. Como puedes ver, casi todas son comentarios. Las sentencias para solicitar recursos al sistema de colas deben estar comentadas. Deben comenzar con `#SBATCH`. Si comienza con dos o más '#', la sentencia será ignorada.
En el ejemplo anterior, las sentencias a tener en cuenta son las siguientes:
#SBATCH --ntasks=1: Número de tareas (procesos). Si utilizas bibliotecas de paralelización como MPI, este número debería ser igual al número de tareas de MPI.#SBATCH --mem=2gb: Memoria RAM total solicitada. Si el trabajo intenta usar más de esta memoria, terminará con un error `out_of_memory`.#SBATCH --time=10:00:00: Tiempo total de ejecución. Cuando se agote este tiempo, el trabajo será cancelado.#SBATCH --constraint=cal: Esto es para seleccionar el tipo de nodos en los que deseas ejecutar el trabajo. "cal" significa cualquier nodo (excepto nodos GPU).#SBATCH --error=job.%J.err: Nombre del archivo donde se guardarán los mensajes de error de la ejecución del programa (%J será reemplazado por el id del trabajo).#SBATCH --output=job.%J.out: Nombre del archivo donde se guardarán los mensajes de salida de la ejecución del programa (%J será reemplazado por el id del trabajo).
En el ejemplo anterior se han incluido algunas declaraciones '##' que serán ignoradas. Se incluyen por si acaso son necesarias, se pueden descomentar. Estas sentencias son:
##SBATCH -J script_2.sh: Esto es para cambiar el nombre bajo el cual aparecerá el trabajo en la cola. Por defecto, se le asigna el mismo nombre que el script SBATCH.##SBATCH --cpus-per-task=1: Esto es para cambiar el número de CPUs solicitadas por cada tarea. Por defecto se asigna 1 CPU por tarea.##SBATCH --constraint=sd: Esto es para que el trabajo solo pueda ingresar a los nodos sd (Intel).##SBATCH --constraint=sr: Esto es para que el trabajo solo pueda ingresar a los nodos sr (AMD).##SBATCH --constraint=bc: Esto es para que el trabajo solo pueda ingresar a los nodos bc (AMD).##SBATCH --gres=gpu:1: Esto es para solicitar GPUs. Primero, las declaraciones deben estar comentadas con "--constraint". El número al final se refiere a cuántas GPUs se están solicitando.##SBATCH --array=1-100: Esto es para usar trabajos de array. Se explicará en la sección Array jobs: how to send lots of jobs
NOTAS IMPORTANTES:
- Todas las comandos #SBATCH deben ir al inicio del archivo, sin líneas comentadas encima de ellas, porque cualquier línea SBATCH después de la primera línea sin comentar será ignorada por slurm.
- Los límites de recursos tienen políticas estrictas. Significa que, si excedes los recursos solicitados, tu trabajo será finalizado.
- Puedes evaluar los recursos que un trabajo ha utilizado efectivamente ejecutando
seff id_trabajocuando ya haya finalizado (seffno funciona si el trabajo está en ejecución). Esto te permitirá ajustar los recursos para una utilización óptima (tus trabajos comenzarán a resolverse más pronto). También puedes usar el nuevo monitor de trabajos en línea para esta tarea. En la sección Monitoring queued jobs, puedes encontrar más detalles al respecto.
Para usuarios antiguos: La nueva versión de Slurm ha cambiado el comando --cpus por --cpus-per-task. Debes actualizar tus scripts para obtener los recursos solicitados.
4.3 - Solicitar GPUs
Como se discutió brevemente en la sección anterior, para solicitar GPUs, las líneas "--constrain" deben estar comentadas (con dos '##'):
##SBATCH --constraint=cal
y la línea
#SBATCH --gres=gpu:1
Debe estar sin comentar (solo un '#'). Si desea utilizar más de una GPU, simplemente cambie el "1" por otro número. Recuerde que nuestros nodos exa tienen 8 GPUs cada uno.
4.4 - Generador de trabajos de muestra
También hemos creado una herramienta que genera un trabajo de muestra completo para algunos programas. Puede ver una lista de trabajos de muestra disponibles con este comando:
gen_sample_job | grep -v NO
Cuando haya localizado el trabajo de muestra deseado, puede generarlo con el siguiente comando:
gen_sample_job
Donde
gen_sample_job gaussian gaussian_job
Nota: No tenemos muchos ejemplos y la mayoría de ellos pueden ser antiguos.
4.5 - Envío de un trabajo
Cuando tenga una versión modificada del archivo script.sh adaptado a sus necesidades, estará listo para enviarlo al sistema de colas. Para hacerlo, simplemente debe ingresar:
sbatch script.sh
Ahora, el trabajo ha sido recibido por el sistema de colas, que buscará los recursos solicitados. Una vez que los recursos estén disponibles, el trabajo comenzará.
En la sección "Monitoreo de trabajos en cola" aprenderá cómo monitorear el estado de sus trabajos. De esta manera, sabrá si el trabajo todavía está buscando un lugar para ser ejecutado (en cola) o si ya está en ejecución.
Nota importante: Notará que si solicitó recursos adaptados a sus necesidades (y no en exceso), su trabajo comenzará mucho más rápido, ya que encontrará un lugar para ser ejecutado mucho más fácilmente. También tenga en cuenta que si solicita menos recursos de los que necesitará su trabajo, el trabajo será eliminado inmediatamente tan pronto como los recursos sean superados por el software.
4.6 - Array Jobs: cómo enviar muchos trabajos
Cuando necesitas enviar un conjunto de trabajos que ejecuten el mismo comando sobre diferentes datos, puedes hacer uso de los trabajos en array. Los trabajos en array son ahora una opción nativa de Slurm, por lo que encontrarás información avanzada sobre ellos en el manual de Slurm.
Para usar trabajos en array, solo necesitas hacer algunos cambios en el archivo de script. En primer lugar, elimina un símbolo de comentario de la línea `--array` (dejándolo solo con un símbolo de comentario '#'):
# Deje un comentario en la siguiente línea para hacer un trabajo en array. Luego se lanzarán N trabajos. En cada uno SLURM_ARRAY_TASK_ID tomará un valor de 1 a 100
#SBATCH --array=1-100
De esta manera, Slurm enviará 100 trabajos, con la única diferencia de que la variable de entorno `SLURM_ARRAY_TASK_ID` variará de 1 a 100. Una forma de utilizarlo para pasar diferentes ficheros de datos al programa para cada ejecución es nombrar los ficheros en forma de "data_0, data_1,..., data_100" y llamar al programa de la siguiente manera:
time my_command data_${SLURM_ARRAY_TASK_ID}
También puedes elegir algunos valores específicos para esta variable, por ejemplo `7,55,87,95,4,2`:
#SBATCH --array=7,55,87,95,4,2
Después de estas modificaciones, debes enviarlo al sistema de cola, usando el comando sbatch normal:
sbatch script.sh
Nota: Si vas a enviar un trabajo en array de más de 1000 trabajos por primera vez, por favor, contáctanos primero.
4.7 - Monitoreo de trabajos en cola
4.7.1 - Comando squeue
En cualquier momento, puedes monitorear la cola de trabajos ejecutando este comando:
squeue
Por defecto, squeue muestra trabajos en formato corto (agrupando trabajos en array juntos). Si necesitas acceder al formato largo, utiliza el indicador `-l`:
squeue -l
4.7.2 - Nuevo monitor de trabajos en línea
Para obtener información más detallada sobre tus trabajos en ejecución, puedes acceder al nuevo monitor de trabajos en línea. Esta utilidad te mostrará detalles en tiempo real sobre el número de CPU y la cantidad de RAM utilizada, y también el uso de GPU y VRAM si corresponde. Para usar el monitor en línea, sigue estas instrucciones:
- Ingresa a https://www.scbi.uma.es/slurm_monitor/admin/login
- Inicia sesión con tus credenciales de usuario de picasso
- Verás una lista de todos tus trabajos en ejecución o finalizados
- Usando los controles de la primera fila, puedes ordenar los trabajos por cualquier columna
- Al utilizar los filtros a la derecha, solo se mostrarán los trabajos que te interesen
- Haz clic en el trabajo deseado
- Verás más detalles en la parte superior y gráficos en tiempo real debajo
- Al hacer clic en los diferentes elementos de la leyenda, puedes ocultar o mostrar su gráfico correspondiente
- Sistema: Puede ser un indicador del uso de disco. Si es alto, deberías usar localscratch
- Nuevo proc: Una línea vertical aparecerá cada vez que se detecte un nuevo proceso. Es útil cuando usas varios programas en tu script.
- Cores reservados: Línea horizontal con los núcleos que se solicitaron.
- RAM reservada: Línea horizontal con los GB de RAM que se solicitaron.
- RAM: RAM realmente utilizada.
- Cores: Núcleos de CPU realmente utilizados.
Recuerda que si ajustas tus recursos solicitados a los que realmente puedes usar, tu trabajo comenzará a resolverse más rápido, ya que encontrará más rápido un lugar para ser ejecutado. Además, más recursos estarán disponibles para otros usuarios en picasso.
4.8 - Cancelación de trabajos
En ocasiones, querrás cancelar un trabajo que ya está en ejecución o en cola. Para hacerlo, solo tienes que tomar el número de identificación del trabajo (primera columna mostrada en squeue) y emitir este comando:
scancel <JOBID>
donde <JOBID> es el número del trabajo que se cancelará.
Para cancelar solo algunos trabajos de un trabajo en array, utiliza este formato:
scancel <JOBID>_[1-50]
En ese ejemplo, habrías cancelado los trabajos del 1 al 50 del trabajo en array con ID JOBID.
4.9 - Uso del sistema de ficheros LOCALSCRATCH
Por defecto, puedes trabajar y crear ficheros temporales en tu sistema de ficheros $FSCRATCH normal, pero a veces puede que necesites usar un programa que genere miles y miles de ficheros temporales muy rápido. Eso no es un comportamiento adecuado para sistemas de ficheros compartidos, ya que cada creación de archivo pequeño realiza algunas solicitudes al almacenamiento compartido para completarse. Si hay miles de ellos, pueden congestionar el sistema en algún momento.
En estos casos extremos, es obligatorio utilizar el sistema de ficheros $LOCALSCRATCH. En situaciones menos extremas, en las que el software ejecuta operaciones de E/S grandes, también puedes aprovechar la aceleración que proporciona el sistema de ficheros Localscratch. Como se ha visto en la sección de hardware, todas las máquinas tienen al menos 900GB de localscratch. Para un uso alto de localscratch, por favor, contáctanos primero.
El sistema de ficheros localscratch es independiente para cada nodo, y por lo tanto, no se comparte entre nodos y no es accesible desde las máquinas de inicio de sesión. Debido a eso, debes entender cómo copiar tus datos allí, usarlos y luego recuperar los resultados importantes de vuelta a tu directorio de inicio (todo hecho dentro del script sbatch). Aquí puedes encontrar un ejemplo que podría ayudarte en estas tareas. No dudes en contactarnos si tienes alguna pregunta.
#!/usr/bin/env bash
# Leave only one comment symbol on selected options
# Those with two commets will be ignored:
# The name to show in queue lists for this job:
##SBATCH -J script_2.sh
# Number of desired cpus (can be in any node):
#SBATCH --ntasks=1
# Number of desired cpus (all in same node):
##SBATCH --cpus-per-task=1
# Amount of RAM needed for this job:
#SBATCH --mem=2gb
# The available nodes are:
# AMD nodes with 256 cores and 683GB of usable RAM
# AMD nodes with 128 cores and 1800GB of usable RAM
# AMD nodes with 128 cores and 439GB of usable RAM
# Intel nodes with 52 cores and 187GB of usable RAM
# The time the job will be running:
#SBATCH --time=10:00:00
# If you need nodes with special features you can select a constraint.
# Please, use cal by default. You will be assigned a node that satisfies your requests.
#SBATCH --constraint=cal
# Change "cal" by "sd" if you want to use Intel nodes and by "sr" if you want to use AMD nodes.
##SBATCH --constraint=sd
##SBATCH --constraint=sr
# To use GPU, comment out the constraint line and uncomment the following line.
##SBATCH --gres=gpu:1
# Set output and error files
#SBATCH --error=job.%J.err
#SBATCH --output=job.%J.out
# Leave one comment in following line to make an array job. Then N jobs will be launched. In each one SLURM_ARRAY_TASK_ID will take one value from 1 to 100
##SBATCH --array=1-100
# To load some software (you can show the list with 'module avail'):
# module load software
# create a temp dir in localscratch
MYLOCALSCRATCH=$LOCALSCRATCH/$USER/$SLURM_JOB_ID
mkdir -p $MYLOCALSCRATCH
# execute there the program
cd $MYLOCALSCRATCH
time program1 $HOME/data/data1 > results
#copy some results back to home
cp -rp your_results $HOME/place_to_store_results
#remove your localscratch files:
if cd $LOCALSCRATCH/$USER; then
if [ -z "$MYLOCALSCRATCH" ]; then
rm -rf --one-file-system $MYLOCALSCRATCH
fi
fi
5 - Copiar ficheros desde/hacia picasso
En algún momento necesitarás copiar ficheros desde o hacia picasso. Tenemos que diferenciar dos casos:
5.1 - Descarga de ficheros desde internet
En caso de que quieras descargar un archivo en picasso desde una URL disponible en internet, puedes hacerlo usando el comando wget en la consola de picasso:
wget
Por ejemplo, para descargar un archivo desde la URL https://www.example.com/file.txt, debes usar:
wget https://www.example.com/file.txt
Es común que el comando wget
- Descarga e instala uno de estos complementos según el navegador web que uses (curlwget para Chrome, cliget para Firefox, curlwget para Edge).
- Inicia la descarga (en tu computadora) del archivo que te interesa, luego detén la descarga.
- Ahora haz clic en el icono del complemento (generalmente en la esquina superior derecha de tu navegador web).
- Debería aparecer el comando wget completo. Copia el comando wget completo.
- Pégalo en picasso y presiona Enter. La descarga debería comenzar.
5.2 - Copiando ficheros desde y hacia picasso
5.2.1 - Comando scp
En caso de que necesites copiar un archivo desde/hacia picasso a/desde tu computadora, puedes usar el comando
scp -r <from_path_file> <to_destination_path>
Este comando se puede utilizar para copiar en ambas direcciones.
Para copiar desde picasso a tu computadora:
scp -r <user>@picasso.scbi.uma.es:<file_path_in_picasso> <file_local_destination>
Puedes obtener la ruta de una carpeta en Picasso usando el comando
pwd
Debes moverte a la carpeta que deseas copiar y ejecutar este comando.
Para copiar desde tu computadora a picasso:
scp <file_local_destination> <user>@picasso.scbi.uma.es:<file_destination_in_picasso>
Para obtener su ruta local en tu computadora, simplemente haz clic en la barra superior del explorador de ficheros y copia la ruta, como puedes ver en la figura
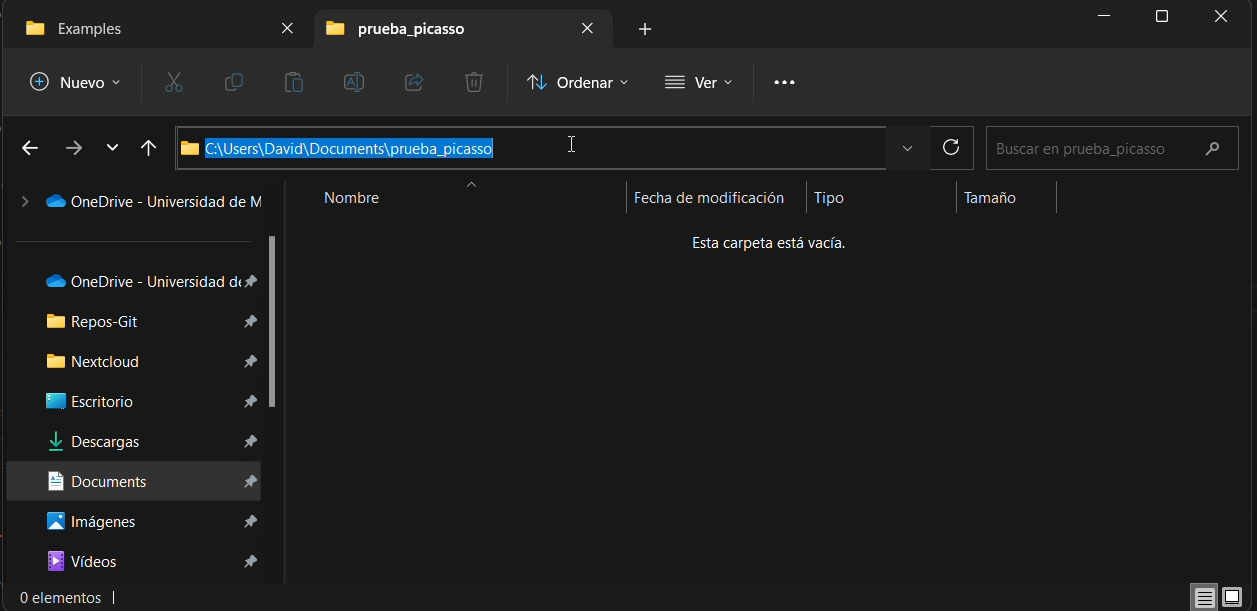
5.2.2 - Comando rsync
Si deseas copiar muchos ficheros, recomendamos el uso del comando rsync, es muy similar a scp, pero rsync puede omitir ficheros ya transferidos, por lo que realiza una sincronización en lugar de una copia completa. La sintaxis es muy similar.
Para copiar desde picasso a tu computadora:
rsync -CazvHu <user>@picasso.scbi.uma.es:<file_path_in_picasso> <file_local_destination>
Para copiar desde tu computadora a picasso:
rsync -CazvHu <file_local_destination> <user>@picasso.scbi.uma.es:<file_destination_in_picasso>
NOTA: Para transferencias pesadas, recomendamos usar el comando rsync, ya que si la transferencia se interrumpe por cualquier motivo, omitirá los ficheros existentes cuando intentes cargarlos nuevamente.
6 - Software
6.1 - Software disponible
Tenemos una amplia variedad de software instalado y listo para usar. Puedes consultar la lista actualizada en nuestra página web (puede estar desactualizada), o ejecutando el siguiente comando en el servidor de inicio de sesión (recomendado):
module avail
Para buscar un software específico
module avail | grep -i software_name
Por ejemplo, para buscar instalaciones de un software como WRF (Weather Research and Forecasting), puedes usar el comando
module avail | grep -i wrf
6.2 - Cómo cargar/descargar software
6.2.1 - Cargar un software
Para cargar un módulo solo tienes que ejecutar el comando
module load software_name
Puedes obtener los nombres de los software con los comandos de la sección anterior.
Por ejemplo, si deseas cargar la versión 4.4.2 compilada de WRF compilada con intel, debes escribir
module load WRF/4.4.2_intel_mpi
Debes incluir el comando de carga del módulo en tu script SBATCH.
También funciona si ejecutas el `module load` en la terminal antes de enviar el trabajo al sistema de encolado, pero no se recomienda debido a su tediosidad. Esto se debe a que cada vez que accedes a Picasso inicias una sesión "limpia" (sin ningún módulo cargado), por lo que tendrías que cargar los módulos cada vez que ingreses a Picasso.
Si deseas ejecutar comandos directamente en la terminal (como abrir un intérprete de una de nuestras versiones de Python), deberás cargar el módulo ejecutándolo en la terminal.
6.2.2 - Listar el software cargado
Para ver los paquetes que has cargado previamente:
module list
6.2.3 - Descargar software
Para descargar cualquier paquete previamente cargado:
module unload software_name Por ejemplo, si deseas descargar el WRF previamente cargado:
module unload WRF/4.4.2_intel_mpi
También puedes usar el siguiente comando para descargar todo el software que hayas cargado. (Nota: si te desconectas de picasso, todo el software se descarga automáticamente).
module purge
6.3 - Compilación de software
Para compilar tu propio software, puedes usar diferentes compiladores (gcc, intel, pgi, ...). Cada software tiene sus propias instrucciones de compilación, pero normalmente puedes compilarlo con diferentes compiladores.
Gcc es el predeterminado, pero el compilador de Intel puede acelerar tu código. Para compilar usando el compilador de Intel, primero debes cargarlo:
module load intel/2024.0.1
7 - Comandos propios de Picasso
Desde el equipo de soporte de Picasso, hemos desarrollado una serie de comandos para ayudar a los usuarios. Estos son los siguientes:
count_files: Este comando devolverá el número de ficheros dentro de las carpetas del directorio actual.free_gpus.sh: Este comando te mostrará las GPU disponibles.resource_efficiency: Este comando genera el gráfico que puedes ver cuando ingresas a Picasso. Te muestra el porcentaje de CPU y RAM utilizados con respecto al total solicitado para los últimos 5 trabajos que se han completado exitosamente. También puedes generar el gráfico para los trabajos que desees pasando los identificadores de los trabajos al comando:
También puedes ver el mensaje de ayuda conresource_efficiency job_id job_id job_id job_id job_idresource_efficiency -h
8 - Preguntas frecuentes
Esta sección contiene respuestas a preguntas frecuentes:
8.1 - ¿Cuántos recursos debo solicitar para mis trabajos?
Es importante ajustar los recursos a tus necesidades. Demasiados pocos recursos resultarán en trabajos cancelados, y demasiados recursos aumentarán el tiempo que tu trabajo necesita para encontrar un lugar donde ejecutarse, también resultando en menos recursos libres para otros usuarios.
Puedes utilizar el monitor de trabajos en línea (explicado en la subsección "Monitoreo de trabajos en cola") para evaluar si estás utilizando los recursos correctamente. También es útil el comando seff id_del_trabajo, una vez el trabajo ha terminado.
Incluso si estás utilizando todos los núcleos que solicitaste, no tiene que significar que se estén utilizando correctamente. Algunos programas no escalan bien.
Como ejemplo, hay programas que usando 64 núcleos resuelven los problemas casi el doble de rápido que cuando se usan 32 núcleos. Sin embargo, otros programas no son tan buenos, y solo pueden mejorar la velocidad en un 10% en tal escenario, o incluso durar más con 64 núcleos que con 32.
Si experimentas este tipo de problema, o si necesitas ayuda para ajustar los recursos, prepara un ejemplo de trabajo que dure aproximadamente 2 horas para finalizar y contáctanos en soporte@scbi.uma.es.
8.2 - Mensaje de error: Conetion refused/The network is not available
Si recibes este mensaje de error, tu IP ha sido bloqueada debido a demasiados intentos de inicio de sesión fallidos. Si no has sido desbloqueado automáticamente en 30 minutos, contáctanos en soporte@scbi.uma.es.
8.3 - Mensaje de error: Remote host identification has changed
Si ves un mensaje con alguno de estos textos: "Remote host identification has changed"; "Es posible que alguien esté haciendo algo malo". Puede ser por varias violaciones de seguridad pero, hemos cambiado nuestra huella digital recientemente (julio de 2021). Si no has conectado desde esta fecha, debes eliminar la clave antigua y usar la nueva. Para hacer esto, por favor lee el mensaje de advertencia completo y identificarás un texto que dice "Puedes usar el siguiente comando para eliminar la clave ofensiva:". Después de eso, se muestra un comando que debes ejecutar con tu ruta personal a las claves SSH. En un sistema Linux será pre-asumiblemente como:
ssh-keygen -R picasso.scbi.uma.es -f
8.4 - ¿Cómo cambio mi contraseña?
Si ya conoces tu contraseña y deseas cambiarla, puedes hacerlo usando el comando:
passwd
Te pedirá tu contraseña actual. Luego, se te pedirá dos veces la nueva contraseña y, eventualmente, se mostrará un mensaje de cambio exitoso.
8.5 - ¿Por qué se cancela mi proceso en el nodo de inicio de sesión?
La máquina de inicio de sesión no es un lugar para ejecutar tu trabajo. Puede usarse para construir scripts, compilar programas, probar que un comando complejo que vas a usar en el script SBATCH se está lanzando correctamente, etc., pero NO para realizar un trabajo real. Todos los programas lanzados se eliminarán automáticamente sin previo aviso cuando utilicen más de 10 minutos de tiempo de CPU.
8.6 - ¿Por qué mi trabajo está en cola durante tanto tiempo?
Probablemente se deba a que los recursos que solicitaste son excesivos. Notarás que si solicitaste recursos adaptados a tus necesidades (y no en exceso), tu trabajo comenzará mucho más rápido, ya que encontrará un lugar para ejecutarse mucho más fácilmente. También ten en cuenta que si solicitas menos recursos de los que necesitará tu trabajo, el trabajo se cancelará inmediatamente tan pronto como los recursos sean excedidos por el software.
Si pediste GPUs para tu trabajo, puedes verificar las GPUs disponibles actualmente ejecutando:
free_gpus.sh
8.7 - ¿Por qué mi trabajo no obtiene los recursos que solicité?
Todas las líneas de programas SBATCH (por ejemplo, #SBATCH --ntasks=8) deben ir al principio del archivo, sin líneas sin comentar encima de ellas, porque cualquier línea SBATCH después de la primera línea sin comentar será ignorada por slurm. Probablemente esto haya sucedido en tu archivo sbatch.
8.8 - Necesito más tiempo para mi trabajo
Los usuarios tienen un límite de tiempo de 3 o 7 días como máximo para el tiempo máximo de trabajo. Pedir más de 3 días es arriesgado, dado que la posibilidad de cualquier tipo de error aumenta con el tiempo.
Si incluso con 7 días no es suficiente para tu trabajo, claramente necesita alguna optimización (paralelismo, división, cambio de software, replanteamiento general, etc.). Puedes contactarnos en soporte@scbi.uma.es si necesitas ayuda para esta tarea.
8.9 - ¿Por qué ha fallado mi trabajo?
Puedes echar un vistazo a los ficheros de registro de errores y salida para obtener pistas sobre lo que sucedió. El error "Command not found" se muestra cuando picasso no puede encontrar el comando que intentas ejecutar. Comúnmente se debe a olvidar incluir un comando de carga de módulo antes de la llamada al software correspondiente.
8.10 - Mensaje de error: cnf
Si tu trabajo intentó usar más recursos de los que solicitaste, el trabajo se cancelará automáticamente. En el caso de que estuviera saturando el sistema de una manera que interfiera con los trabajos de otros usuarios o si los recursos reservados para él se subutilizaran dramáticamente, lo cancelaremos manualmente.
8.11 - ¿Por qué se ha cancelado mi trabajo?
Si tu trabajo intentó usar más recursos de los que solicitaste, el trabajo se cancelará automáticamente. En el caso de que estuviera saturando el sistema de una manera que interfiera con los trabajos de otros usuarios o si los recursos reservados para él se subutilizaran dramáticamente, lo cancelaremos manualmente.
8.12 - Mensaje de error: Controlador de falta de memoria
Si tu trabajo intentó usar más RAM de la que solicitaste, el trabajo se cancelará automáticamente. Por favor, aumenta la cantidad de RAM solicitada en tu archivo sbatch y confirma que sigue la estructura #SBATCH `--mem=2gb`
8.13 - ¿Por qué no puedo editar ni crear nuevos ficheros?
Probablemente hayas excedido la cuota. Usa el comando
quota
para comprobarlo. Recuerda que puedes alcanzar tanto la cuota suave como la dura debido al número de ficheros escritos o al tamaño de estos ficheros. Cuando hayas eliminado suficientes ficheros, podrás volver a crear y editar ficheros. Para obtener más información, consulta la sección "Sistema de ficheros".
Si no excediste tu cuota, entonces es posible que estés intentando escribir en una carpeta o editar un archivo en el que no tienes permiso de escritura.
8.14 - Necesito más espacio o cuota de ficheros
Recuerda que tienes dos ubicaciones separadas para tus ficheros, el $HOME (donde deberías almacenar los datos de entrada, tus propios scripts desarrollados, resultados finales y otros datos importantes) y el $FSCRATCH (donde deberías ejecutar tu trabajo).
Verifica que no conservas ningún archivo antiguo no deseado y elimínalos si los hay. Si necesitas aumentar la cuota debido a algún paquete conda / python, debes saber que no tienes que instalar el entorno completo en tu usuario. Es suficiente con ejecutar `module load anaconda` y luego `pip install` solo para el resto de los paquetes que no están en el módulo.
Si ninguno de los anteriores te ayuda, puedes contactarnos en soporte@scbi.uma.es.







